

「ガチ実装」ではなくて、
“頭の中のモヤモヤを形にしてみたメモ” くらいの温度感で読んでもらえればうれしいです。
はじめに
こんにちは、末端技術者ニコラです。
今日は、画像処理でいつもモヤモヤしているのに、
メーカは絶対に教えてくれないテーマ…
「OCR(光学文字認識)のアルゴリズムってどうなってるの?」
について、Excelを使って自分なりに考えてみた話を書いていきます。
ITエンジニアの転職なら【TechGO(テックゴー)】なぜOCRのアルゴリズムは教えてもらえないのか
画像処理をやっていると、こんな質問がよく飛んできます。
- 「この正解画像に対して、なんで相関値が82%なんですか?」
- 「この2枚、見た目ほぼ同じなのに、なんでこっちはマッチング率が下がるんですか?」
正直なところ、
現場で聞かれても、ほとんどの人はちゃんと説明できないと思います。
理由はシンプルで、
- OCRのアルゴリズムは各社のノウハウの塊
- つまり、ビジネス的な生命線そのもの
だからです。
過去、自分もメーカーさんに対して何度もこう聞きました。
- 「この値の計算式、開示してもらえませんか?」
- 「変動要因だけでもいいので教えてもらえませんか?」
でも、返ってくる答えはだいたいこんな感じ。
- 「社外秘なのでお伝えできません」
- 「内部アルゴリズムの詳細は非公開です」
頭では分かってるんですが、報告会とかがあると
やっぱり「なんとか説明のタネが欲しい」と思っちゃうんですよね。
そもそも何が疑問だったのか:相関値って何者?
OCRに限らず、画像処理ではよく
- マッチング率
- 相関値
- 類似度
みたいな数字が出てきます。
ここでの素朴な疑問はこれです。
- 「正解画像と見本画像を比べてるのは分かる」
- 「でも、その“数字の出方”がイメージしづらい」
報告会では、知らない人からこんな質問が飛びます。
- 「90%と80%の差って、画像的に何が違うの?」
- 「なんでこのパターンだけ60%台なんですか?」
本音を言うと、
- 「いや、そこまでメーカーは教えてくれないんですよ…」
で終わらせたいところですが、
説明責任がある立場だとそれでは済まないんですよね。
そこで、
「だったら、自分で“それっぽいアルゴリズム”をExcelで作ってみよう」
と思ったのが今回のネタです。
今回作ったExcel簡易OCRのコンセプト
やったことをざっくり書くと、こうです。
- Excelで 0〜255 の数値をセルに入れ、それを色として表示
- 1セル=1画素として、文字「A」の画像を作る
- その画像を 4×4 の 16ブロックに分割
- 各ブロックの「明るさの合計(または平均)」を計算
- その16個の値を「1本のベクトル」と見なす
- 正解パターンと入力パターンのベクトル差分から「相関値っぽいもの」を計算
イメージとしては、
- 正解画像:ベクトル V
- 検査画像:ベクトル W
- V と W が近い(=0)ほど「相関が高い」
- V と W が離れていると「相関が低い」
という感じです。
Excelでの具体的な手順
ここは、実際にブログに図を入れると映えるところです。
ユーザーさんが画像作る前提で、「ここに図を入れると良さげ」というコメントも付けておきます。
①Excelで0〜255を色として表示する設定
やりたいことは、
- セルに 0〜255 の値を入れる
- 条件付き書式などで、
値に応じてグレーの濃淡に変える(0=黒、255=白)
これで「簡易グレースケール画像」ができます。
②文字「A」をセル塗りつぶしで描く
次に、Excel上でドット絵を描く感覚で文字「A」を作ります。
- たとえば 20×20 マスを用意
- 文字の輪郭部分を 0(黒)に近い値
- 背景部分を 255(白)に近い値
にして、「A」の形をセルの塗りつぶしで作るイメージです。
- 「Excelで描いたグレースケールの“A”」

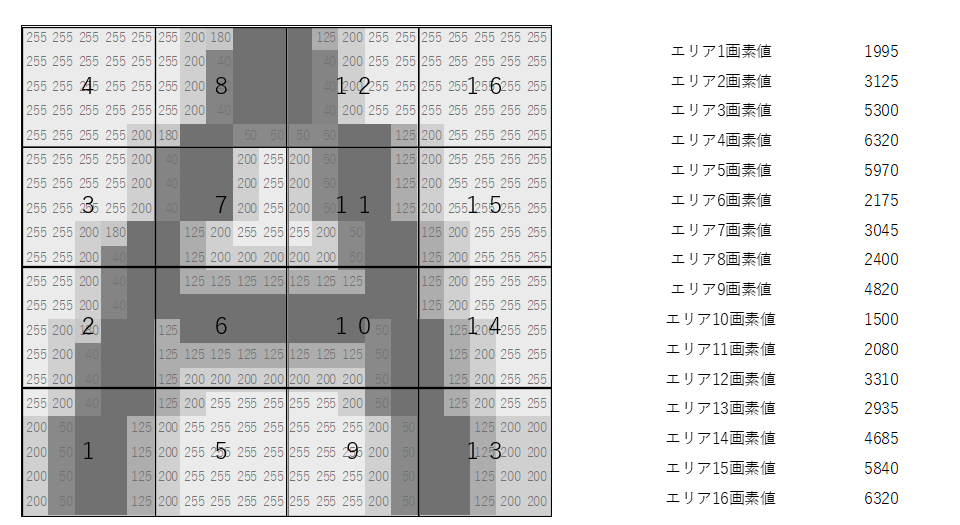
③画像を16ブロック(4×4)に分割する
作った「A」画像を、4×4の16ブロックに分けます。
- 全体:16×16セルとした場合
- 1ブロック:4×4セル
- それが 4×4 並んで、合計16ブロック
各ブロックごとに、
- 明るさの合計 or 平均
を計算して、1エリア = 1つの数値に縮約します。
結果的に、
- エリア1:S1
- エリア2:S2
- …
- エリア16:S16
という 16次元の数値セットができます。
これが、その画像を表現する特徴ベクトル になります。
ベクトル差分で「それっぽい相関値」を出してみる
次に、この特徴ベクトルを使って
「正解画像」と「入力画像」の類似度を計算していきます。
①ベクトルの準備
- 登録画像のベクトル:V = (V1, V2, …, V16)
- 撮像画像のベクトル:W = (W1, W2, …, W16)
例えば、
- V:きれいなフォントの「A」 ※下記画像の左
- W:少し太った「A」、傾いた「A」など ※下記画像の真ん中
を用意して、どのくらい値が変わるかを見ます。

②差分ベクトルと距離
まずは素朴な差分を考えます。
- 差分ベクトル D = V − W = (V1−W1, V2−W2, …, V16−W16)
この差分が小さいほど、画像として似ていると考えられます。
距離としては、例えば
- 絶対値の合計:Σ |Vi − Wi|
- 二乗和:Σ (Vi − Wi)²
などを使うことができます。
ここから、
- 距離が 0 に近い → そっくり
- 距離が大きい → 似ていない
と解釈します。
③相関値っぽいスコアに変換し比較!
距離だけだと「小さいほど良い」なので、
人間が見慣れている「0〜1の相関値っぽいもの」に変換してみます。
イメージとしては、
- 距離 = 0 のとき → 相関値 = 1.0
- 距離 = 大きいほど → 相関値 → 0に近づく
みたいな単調減少の関数を用意すればOKです。
今回は、「すべて0の画像」と「255の画像」を用意し、その差分を最大=相関値0と仮定しました。

そして実際に比較してみた。
比較① : 似ているAを作って相関値を出す

95% ・・・まぁ比較するものが少ないのでこのくらいの数値かなという印象。
比較② : 崩れた「A」と比較

83% ・・・この場合は閾値95%くらいにしておかないとまずいね という印象。
実際のOCRアルゴリズムとの違いと限界
もちろん、ここまでやっておいてなんですが…
実際のOCRはこんな単純なものではありません。
現実のOCRは、
- 前処理(ノイズ除去、二値化、正規化、回転補正)
- 特徴量抽出(エッジ、局所特徴、ヒストグラムなど)
- 機械学習
といった、いろんな処理が組み合わさっています。
今回のExcel実験は、
- グレースケールの合計値をブロックごとにまとめた
- 16次元のベクトルで「それっぽい距離」を計算した
だけなので、かなりラフなモデルです。
具体的な限界としては、
- 少し文字が傾くと途端に値が変わる
- フォント差・線の太さに弱い
- ノイズや汚れをうまく扱えない
- 文字位置がずれるとブロック分けの意味が崩れる
などなど。
「現場にそのまま導入しろ」と言われたら、
普通に無理です。笑
それでもこのExcel実験が役に立つ場面
じゃあ、「こんなラフなモデル、やる意味あるの?」というと、
個人的にはかなり意味あると思っています。
理由は:
- 報告会での説明がしやすくなる
- 「内部アルゴリズムは開示されていませんが、ざっくりいうとこんなイメージです」
- 「ブロックごとに明るさを数値化して、そのベクトルの違いを見ていると思ってください」
という例え話に使える
- 自分の頭の中が整理される
- 「相関値」とか「マッチング率」という言葉が
「ベクトルの距離」「特徴量の差分」みたいなイメージで語れるようになる
- 「相関値」とか「マッチング率」という言葉が
- 現場でのチューニング方針が立てやすくなる
- 「ここを変えると、相関値が下がる理由」が感覚的に理解できると
- しきい値
- 照明条件
- 画素分解能
の設計がしやすくなる
- 「ここを変えると、相関値が下がる理由」が感覚的に理解できると
まとめ:ブラックボックスを100%開けなくても、イメージは持てる
最後に、今回のポイントをざっくりまとめます。
- OCRのアルゴリズムは各社の生命線なので、基本的には開示されない
- でも、現場では「なんでこの相関値になるの?」という質問が必ず飛んでくる
- そこでExcelで
- 0〜255のグレースケール画像を作り
- 文字「A」をセルで描き
- 16ブロックに分けて合計値を取り
- ベクトル差分から“それっぽい”相関値を作ってみた
- 実際のOCRとは全然違うけれど、
- 「ベクトルで似ているかどうかを見ている」
というイメージを掴むにはちょうどいい
- 「ベクトルで似ているかどうかを見ている」
- ブラックボックスを完全に開けることはできないけど、
概念レベルで説明できるだけでも現場での説得力はかなり変わる
もしこの記事を読んで
- 「自社のフォントパターンでもやってみようかな」
- 「ノイズをわざと足して相関値の変化を見てみようかな」
と思ってもらえたら、このExcel遊びは成功かなと思います。

この記事へのコメント