
はじめに
こんにちは、末端技術者ニコラです。
今日は、画像処理でいつもモヤモヤしているのに、
メーカは絶対に教えてくれないテーマ…
「OCR(光学文字認識)のアルゴリズムってどうなってるの?」
について、Excelを使って自分なりに考えてみた話を書いていきます。
“頭の中のモヤモヤを形にしてみたメモ” という感覚で読んでもらえればうれしいです。
この記事はIT・生技・保全エンジニアに向けに画像処理OCRのアルゴリズムを可視化し説明しやすくすることを目的に作成しています。
アルゴリズムの理解→Q&Aという順に説明します。
なぜOCRのアルゴリズムは教えてもらえないのか
画像処理をやっていると、こんな質問がよく飛んできます。
- 「この正解画像に対して、なんで相関値が82%なんですか?」
- 「この2枚、見た目ほぼ同じなのに、なんでこっちはマッチング率が下がるんですか?」
正直なところ、
現場で聞かれても、ほとんどの人はちゃんと説明できないと思います。
理由はシンプルで、
- OCRのアルゴリズムは各社のノウハウの塊
- つまり、ビジネス的な生命線そのもの
だからです。
過去、自分もメーカーさんに対して何度もこう聞きました。
- 「この値の計算式、開示してもらえませんか?」
- 「変動要因だけでもいいので教えてもらえませんか?」
でも、返ってくる答えはだいたいこんな感じ。
- 「社外秘なのでお伝えできません」
- 「内部アルゴリズムの詳細は非公開です」
頭では分かってるんですが、報告会とかがあると
やっぱり「なんとか説明のタネが欲しい」と思っちゃうんですよね。
そもそも何が疑問だったのか:相関値って何者?
OCRに限らず、画像処理ではよく
- マッチング率
- 相関値
- 類似度
みたいな数字が出てきます。
ここでの素朴な疑問はこれです。
- 「正解画像と見本画像を比べてるのは分かる」
- 「でも、その“数字の出方”がイメージしづらい」
報告会では、知らない人からこんな質問が飛びます。
- 「90%と80%の差って、画像的に何が違うの?」
- 「なんでこのパターンだけ60%台なんですか?」
本音を言うと、
「いや、そこまでメーカーは教えてくれないんですよ…」
で終わらせたいところですが、
説明責任がある立場だとそれでは済まないんですよね。
そこで、
「だったら、自分で“それっぽいアルゴリズム”をExcelで作ってみよう」
と思ったのが今回のネタです。
今回作ったExcel簡易OCRのコンセプト
やったことをざっくり書くと、こうです。
- Excelで 0〜255 の数値をセルに入れ、それを色として表示
- 1セル=1画素として、文字「A」の画像を作る
- その画像を 4×4 の 16ブロックに分割
- 各ブロックの「明るさの合計(または平均)」を計算
- その16個の値を「1本のベクトル」と見なす
- 正解パターンと入力パターンのベクトル差分から「相関値っぽいもの」を計算
イメージとしては、
- 正解画像:ベクトル V
- 検査画像:ベクトル W
- V と W が近い(=0)ほど「相関が高い」
- V と W が離れていると「相関が低い」
という感じです。
Excelでの具体的な手順
①Excelで0〜255を色として表示する設定
やりたいことは、
- セルに 0〜255 の値を入れる
- 条件付き書式などで、
値に応じてグレーの濃淡に変える(0=黒、255=白)
これで「簡易グレースケール画像」ができます。
②文字「A」をセル塗りつぶしで描く
次に、Excel上でドット絵を描く感覚で文字「A」を作ります。
- たとえば 20×20 マスを用意
- 文字の輪郭部分を 0(黒)に近い値
- 背景部分を 255(白)に近い値
にして、「A」の形をセルの塗りつぶしで作るイメージです。
- 「Excelで描いたグレースケールの“A”」

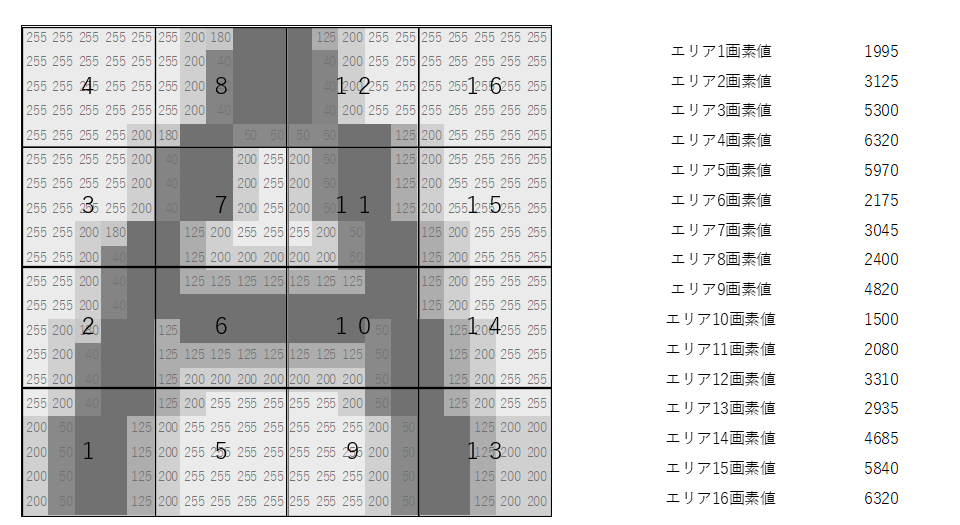
③画像を16ブロック(4×4)に分割する
作った「A」画像を、4×4の16ブロックに分けます。
- 全体:16×16セルとした場合
- 1ブロック:4×4セル
- それが 4×4 並んで、合計16ブロック
各ブロックごとに、
- 明るさの合計 or 平均
を計算して、1エリア = 1つの数値に縮約します。
結果的に、
- エリア1:S1
- エリア2:S2
- …
- エリア16:S16
という 16次元の数値セットができます。
これが、その画像を表現する特徴ベクトル になります。
ベクトル差分で「それっぽい相関値」を出してみる
次に、この特徴ベクトルを使って
「正解画像」と「入力画像」の類似度を計算していきます。
①ベクトルの準備
- 登録画像のベクトル:V = (V1, V2, …, V16)
- 撮像画像のベクトル:W = (W1, W2, …, W16)
例えば、
- V:きれいなフォントの「A」 ※下記画像の左
- W:少し太った「A」、傾いた「A」など ※下記画像の真ん中
を用意して、どのくらい値が変わるかを見ます。

②差分ベクトルと距離
まずは素朴な差分を考えます。
- 差分ベクトル D = V − W = (V1−W1, V2−W2, …, V16−W16)
この差分が小さいほど、画像として似ていると考えられます。
距離としては、例えば
- 絶対値の合計:Σ |Vi − Wi|
- 二乗和:Σ (Vi − Wi)²
などを使うことができます。
ここから、
- 距離が 0 に近い → そっくり
- 距離が大きい → 似ていない
と解釈します。
③相関値っぽいスコアに変換し比較!
距離だけだと「小さいほど良い」なので、
人間が見慣れている「0〜1の相関値っぽいもの」に変換してみます。
イメージとしては、
- 距離 = 0 のとき → 相関値 = 1.0
- 距離 = 大きいほど → 相関値 → 0に近づく
みたいな単調減少の関数を用意すればOKです。
今回は、「すべて0の画像」と「255の画像」を用意し、その差分を最大=相関値0と仮定しました。

そして実際に比較してみた。
比較① : 似ているAを作って相関値を出す

95% ・・・まぁ比較するものが少ないのでこのくらいの数値かなという印象。
比較② : 崩れた「A」と比較

83% ・・・この場合は閾値95%くらいにしておかないとまずいね という印象。
実際のOCRアルゴリズムとの違いと限界
もちろん、ここまでやっておいてなんですが…
実際のOCRはこんな単純なものではありません。
現実のOCRは、
- 前処理(ノイズ除去、二値化、正規化、回転補正)
- 特徴量抽出(エッジ、局所特徴、ヒストグラムなど)
- 機械学習
といった、いろんな処理が組み合わさっています。
今回のExcel実験は、
- グレースケールの合計値をブロックごとにまとめた
- 16次元のベクトルで「それっぽい距離」を計算した
だけなので、かなりラフなモデルです。
具体的な限界としては、
- 少し文字が傾くと途端に値が変わる
- フォント差・線の太さに弱い
- ノイズや汚れをうまく扱えない
- 文字位置がずれるとブロック分けの意味が崩れる
などなど。
「現場にそのまま導入しろ」と言われたら、
普通に無理です。笑
それでもこのExcel実験が役に立つ場面
じゃあ、「こんなラフなモデル、やる意味あるの?」というと、
個人的にはかなり意味あると思っています。
理由は:
- 報告会での説明がしやすくなる
- 「内部アルゴリズムは開示されていませんが、ざっくりいうとこんなイメージです」
- 「ブロックごとに明るさを数値化して、そのベクトルの違いを見ていると思ってください」
という例え話に使える
- 自分の頭の中が整理される
- 「相関値」とか「マッチング率」という言葉が
「ベクトルの距離」「特徴量の差分」みたいなイメージで語れるようになる
- 「相関値」とか「マッチング率」という言葉が
- 現場でのチューニング方針が立てやすくなる
- 「ここを変えると、相関値が下がる理由」が感覚的に理解できると
- しきい値
- 照明条件
- 画素分解能
の設計がしやすくなる
- 「ここを変えると、相関値が下がる理由」が感覚的に理解できると
OCRの種類と、今回のExcel実験の“立ち位置”
ここまで「Excelで自作したなんちゃってOCR」の話をしてきましたが、
そもそも世の中のOCRって、どんな種類があるのか?
その中で今回やっていることはどこに位置するのか?を、ざっくり整理しておきます。
「アルゴリズムは企業秘密です」とメーカに言われても、
ざっくりとした“地図”を頭に持っておくだけで、報告会での説明のしやすさがだいぶ変わります。
OCRのざっくり3カテゴリ
世の中のOCR(光学的文字認識)は、ざっくり分けると次の3種類に分類できます。
- テンプレートマッチング型
- ルールベース/特徴量ベース型
- 機械学習・ディープラーニング型
もちろん、実際の製品はこれらを組み合わせていることが多いですが、
頭の中ではこの3つに整理しておくとスッキリします。
① テンプレートマッチング型OCR
今回、Excelでやっているのがほぼこれです。
考え方は超シンプルで、
「正解画像(テンプレート)と、今の画像がどれくらい似ているかを数値化する」
というものです。
- 入力画像を決まったサイズに切り出す
- グレースケールや2値画像にする
- テンプレート画像と、画素ごとに差を取る
- その差の“小ささ”をスコア(相関値)にする
今回の記事では、
- 画素をそのまま比べるのではなく、
16ブロックに分けて「ブロックごとの濃さ」をベクトルにする - そのベクトル同士の差(距離)を、
「どれくらい似ているか?=相関値っぽいもの」に変換する
という形で、テンプレートマッチングの一番原始的なイメージをExcel化しています。
この方式を実装して分かるメリット・デメリットはざっくりこんな感じです。
- メリット
- 実装が簡単
- 計算コストも少なく、組み込みやPCでサクサク動く
- フォント・位置・明るさがある程度固定なら、十分実用になる
- デメリット
- 位置ズレ・回転・拡大縮小に弱い
- フォントや太さが変わると一気に相関値が落ちる
- ノイズ・ムラにも影響を受けやすい
工場の決まった印字・固定フォント・固定位置を読むような用途では、
今でもこの系統の手法がベースになっていることが多いです。
② ルールベース/特徴量ベース型
テンプレートマッチングより一歩進んだのがこちら。
発想としては、
「画像1枚1枚の画素全部を見るのはしんどいから、
文字の特徴をうまく抜き出して、それを比べよう」
というやり方。
例えば:
- 線の本数や向き
- 交点の数
- 外形(輪郭)の形状
- 重心位置や縦横比
- 端点・角の数 …など
を抽出して、「Aっぽい特徴」「Bっぽい特徴」を判断する、
ルールベース or 特徴量ベースのOCRです。
ほとんどの計測器メーカーがこちらを取り入れているとお聞きしてます。
Excelの実験はここまではやっていませんが、濃淡差にプラスして上記の形状比較を入れることでさらに柔軟に対応した形です。
③ 機械学習・ディープラーニング型OCR
最近のクラウドOCRや、手書き文字も読める高性能なやつは、だいたいこれです。
- 大量の文字画像(学習データ)を用意する
- ディープラーニング
- 「A」「B」「C」…に分類する識別器として使う
という流れで、“人が特徴量やルールを設計する”のではなく、
「特徴の抽出も、判定ルールも、全部モデルに学習させる」
という思想です。
- メリット
- フォント違い・手書き・ノイズ・傾きなどに強い
- 追加の学習で、まだ見たことのないパターンにも対応しやすい
- デメリット
- 学習に大量のデータ・計算資源が必要
- モデルの中身は基本ブラックボックスになりやすい
- 「なぜこの相関値になったのか」を説明しづらい
筆者もAI検査を導入した経験がありますが、一番困ったことは
「どれだけ覚えさせればNGターゲットをNGと言ってくれるか。」
が分かりません。
ルールベースの場合はNGのものを判定する処理にして、閾値を厳しくすれば確実にNGと言ってくれます。
そのため現場からすると、
「なんかよく分からんけど、NGって判定してくれる黒箱(ブラックボックス)」
という立ち位置になりがちです。
今回のExcel実験はどこに位置するのか?
整理すると、今回の記事でやっていることは、
OCR全体の中の
→ テンプレートマッチング型
その中でも
→ 「ブロックごとの濃度ベクトルを使った、超シンプルな類似度計算」をExcelで可視化してみた、という位置づけです。
つまり、
「メーカが見せてくれない相関値計算のイメージを、自分でおもちゃモデルとして再現してみたもの」
だと思ってもらえればOKです。
実機のOCRはここに、
- 位置補正
- 傾き補正
- 二値化・ノイズ除去
- 特徴量設計
- 学習・統計的処理
などなど、いろんな「計算」を盛り込んでいるイメージです。
全部を自作するのは現実的ではありませんが、
このExcelモデルを通じて、
- 「相関値って、本質的にはこういう“似てる度”なんだよね」
- 「だからズレるとスコア落ちるし、ノイズが乗ると悪化する」
という感覚を持っておくだけでも、
メーカとの会話や報告会での説明がかなり楽になるかと思います。
よくある質問(FAQ)
最後に、現場でよく聞かれそうな質問をいくつかピックアップして、
Q&A形式でまとめておきます。
Q1. Excelの簡易モデルでも、現場検討に使えますか?
A. 「実運用に直接使う」のは無理ですが、 考え方を共有するツールとしては使えます。
例えば:
- 報告会で「相関値って何ですか?」と聞かれたとき
- 「なぜこの画像は80%で、こっちは60%なんですか?」と説明を求められたとき
「こうやってブロックごとに濃さをベクトルにして、差を取ってるイメージです」
とExcel画面を見せながら説明すると、
非エンジニア層にもかなり伝わりやすくなります。
また、
- 明るさを少し変えてみたとき
- 文字の太さを少し変えてみたとき
- 1ブロック分ずらしてみたとき
に、Excel上で相関値がどう変わるかを見ることで、
「アルゴリズムというより、入力側(照明・位置決め)を安定させるのがどれだけ大事か」
を、チーム内で共有する材料にもなります。
Q2. 相関値は何%以上ならOKと決めればいいですか?
A. 「一律で〇%」という正解はありません。
現場ごとの許容ミス率と、実データの分布から決める必要があります。
ざっくり手順にするとこんな感じです。
- 正解サンプルをそこそこの枚数集める(実ワーク)
- そのサンプルで相関値の分布を取る(最低・平均・標準偏差など)
- NGサンプルもいくつか用意して、相関値の分布を見る
- 「誤読をどこまで許容するか」を現場と相談しつつ、
- 正解のうち◯%以上は通したい
- NGは限りなくゼロに近づけたい
というバランスでしきい値を決める
Excelモデルで遊ぶときも、
- 正常パターンの相関値がだいたいどの範囲に集まるか
- わざと崩したパターンがどこまで落ちるか
を確認しておくと、
「80%以上ならOK」といった“なんとなく”ではない説明ができるようになります。
Q3. メーカがアルゴリズムを開示してくれないのに、どうやって改善すればいい?
A. 「中身を理解して何とかする」のではなく、
入力画像の画像処理を調整し、閾値をユーザー側で設定する世界。
メーカがアルゴリズムを開示しないのは、
- 特許・ノウハウの塊だから
- そこを開示するとビジネスにならないから
- 悪用されたり、無茶な改造をされると保証しきれないから
という事情があります。
ユーザー側でやるべきことは、むしろ
- 照明条件を安定させる
- カメラ・レンズ・距離・トリガを安定させる
- ワーク位置・姿勢のバラつきを減らす
- 正しいサンプルで「学習」「画像登録」をやり直す
- 閾値・相関値の閾値を現場とすり合わせる
といった入力側とパラメータ側のチューニングです。
今回のExcelモデルのように、
「似てる度を数値にしているだけなんだよね」
という理解を持っていると、
- メーカ:「もう少し学習枚数を増やしてください」
- メーカ:「このしきい値を少し下げてみてください」
と言われたときも、
「あぁ、あのベクトルの分布を増やして、境界を動かしてるイメージね」
と腹落ちした状態で対応できるので、ムダにイライラしなくて済みます。
Q4. テンプレマッチング型とディープラーニング型って、何が一番違う?
A. 一言でいうと、 テンプレマッチングは「ルールが見える」(見えるといってもユーザーは概念的なものだけ)、 ディープラーニングは「ルールを学習させる黒箱」です。
- テンプレートマッチング
- テンプレ画像と画素ごとの差や相関を直接見て判断
- 挙動がイメージしやすい(今回のExcelモデルのように)
- フォント・位置・傾きが安定しているときに強い
- ディープラーニング
- 大量のデータから「良い特徴量」と「判定ルール」をモデルが自動で作る
- 手書き・フォント違い・ノイズなどへの耐性が高い
- ただし「なぜこの結果なのか」を人間が説明しにくい
両方使用したことがある筆者からすると、
- テンプレマッチング:
条件をきちんとコントロールできるラインで、NGの境界がユーザー側ではっきりしている対象向け - ディープラーニング:
現実的に条件を揃えきれない、様々な判断因子がある対象向け
くらいにイメージしておくと、
「どっちを採用すべきか」を議論するときの整理がしやすくなります。
Q5. 自前でOCRを作ったほうがいい場面ってありますか?
A. よほど用途が限定されているか、研究目的でなければ、 基本は「メーカ製を使い倒す一択」でいいです。
Excelモデルで遊んでみると分かりますが、
- 位置ズレや傾き
- フォント差・印字ムラ
- 照明条件の変化
- 汚れ・かすれ
などを全部自前のアルゴリズムでカバーしようとすると、 あっという間に泥沼になります。
今は餅は餅屋の時代です。
- テストケースの作成
- 誤読時の保証
- バージョン管理
- 不具合対応
まで含めて考えると、
「画像処理まるごと自社開発」のメリットは、実はほとんどない
というのが正直なところです。
今回のExcelモデルは、
- メーカに頼り切りではなく、「原理のイメージは自分の頭に持っておく」
- 報告会や仕様検討のときに、自分の言葉で説明できるようにする
ための“理解装置”として使う、
くらいの距離感が一番おいしいと思っています。
こういった全体マップとFAQを頭の片隅に置きつつ、
Excelモデルで遊んでみると、
「メーカはアルゴリズム教えてくれないけど、
なんとなく中でやっていることはイメージできている」
という、“ちょうどいい理解レベル”に持っていけるはずです。
まとめ:ブラックボックスを100%開けなくても、イメージは持てる
最後に、今回のポイントをざっくりまとめます。
- OCRのアルゴリズムは各社の生命線なので、基本的には開示されない
- でも、現場では「なんでこの相関値になるの?」という質問が必ず飛んでくる
- そこでExcelで
- 0〜255のグレースケール画像を作り
- 文字「A」をセルで描き
- 16ブロックに分けて合計値を取り
- ベクトル差分から“それっぽい”相関値を作ってみた
- 実際のOCRとは全然違うけれど、
- 「ベクトルで似ているかどうかを見ている」
というイメージを掴むにはちょうどいい
- 「ベクトルで似ているかどうかを見ている」
- ブラックボックスを完全に開けることはできないけど、
概念レベルで説明できるだけでも現場での説得力はかなり変わる
もしこの記事を読んで
- 「自社のフォントパターンでもやってみようかな」
- 「ノイズをわざと足して相関値の変化を見てみようかな」
と思ってもらえたら、このExcel遊びは成功かなと思います。
本記事は学習目的の情報提供です。実際の電気工事・設計・配線・機器選定・部材選定・改造は、法令・社内基準に従い、有資格者および責任者の管理下で実施してください。現場条件により最適解は変わるため、必ずメーカー仕様書・設計基準・安全規程・JISを確認のうえ判断してください。


この記事へのコメント